Service Design as Code: A Practical Guide to the Proof of Concept
The concept is one thing; proving it is another. Here's a complete twelve-week Proof of Concept for Service Design as Code — covering tooling choices, schema design, and a phased delivery plan, scoped to the five core ITIL® Service Operation processes.
Series: Service Design as Code, Post #2
Service Design as Code — A Practical Guide to the Proof of Concept
How to Version-Control Your ITIL® Service Operation Processes and Stop Configuration Drift Before It Starts
If you work in managed IT services, you almost certainly have a Service Design Document somewhere. It might be a Word file on SharePoint, a PDF buried on a network drive, or — if you are particularly optimistic — a Confluence page that was last edited before the last major restructure. It describes how your services are designed to work. And if you are honest with yourself, it probably does not reflect how they actually work today.
That gap between documented design and operational reality is not laziness. It is a predictable outcome of treating service design as a document rather than a validated, living artefact. Configuration changes get made under pressure. SLA thresholds get quietly adjusted. Escalation paths evolve through institutional memory rather than through a formal change. Over time, the document and the platform silently diverge — and nobody notices until something goes wrong.
Service Design as Code (SDaC) is the practice of expressing ITSM service design artefacts as version-controlled, machine-readable schema files, rather than static documents. This post covers everything you need to understand the concept, make an informed tooling decision, and run a twelve-week Proof of Concept — scoped to the five core ITIL® Service Operation processes.
1. What Is Service Design as Code — And Why Does It Matter?
The core idea is straightforward: take the structured information that currently lives in Word documents and PDFs — SLA thresholds, priority matrices, escalation paths, approval workflows, access provisioning rules — and express it instead as YAML or JSON schema files stored in a Git repository.
This is not a new concept. Infrastructure as Code (IaC) applied exactly this thinking to servers and networks, and it transformed how engineering teams managed infrastructure. SDaC applies the same discipline to the ITSM operational layer — the processes and configurations that govern how services are run day to day.
The benefits are material and practical:
- Version control — every change to your service design is tracked, attributed, and reversible. Your Git history is your audit trail.
- Automated validation — schema files are validated automatically on every commit. A design that does not conform to the defined structure does not merge.
- Documentation generation — your Service Design Document is no longer something you maintain manually. It is generated from the validated schema.
- Drift detection — a comparator script queries your live ITSM platform and flags the moment the live configuration diverges from the schema-defined design.
- Consistent onboarding — new service engagements are stood up from a validated, version-tagged baseline rather than from tribal knowledge or a copied document of uncertain vintage.
In my opinion, the most undervalued benefit is the audit trail. When a client asks why a process is configured a particular way, the answer should not be "it's always been like that." With SDaC, the answer is: here is the commit, here is the approver, here is the date, and here is the rationale in the commit message.
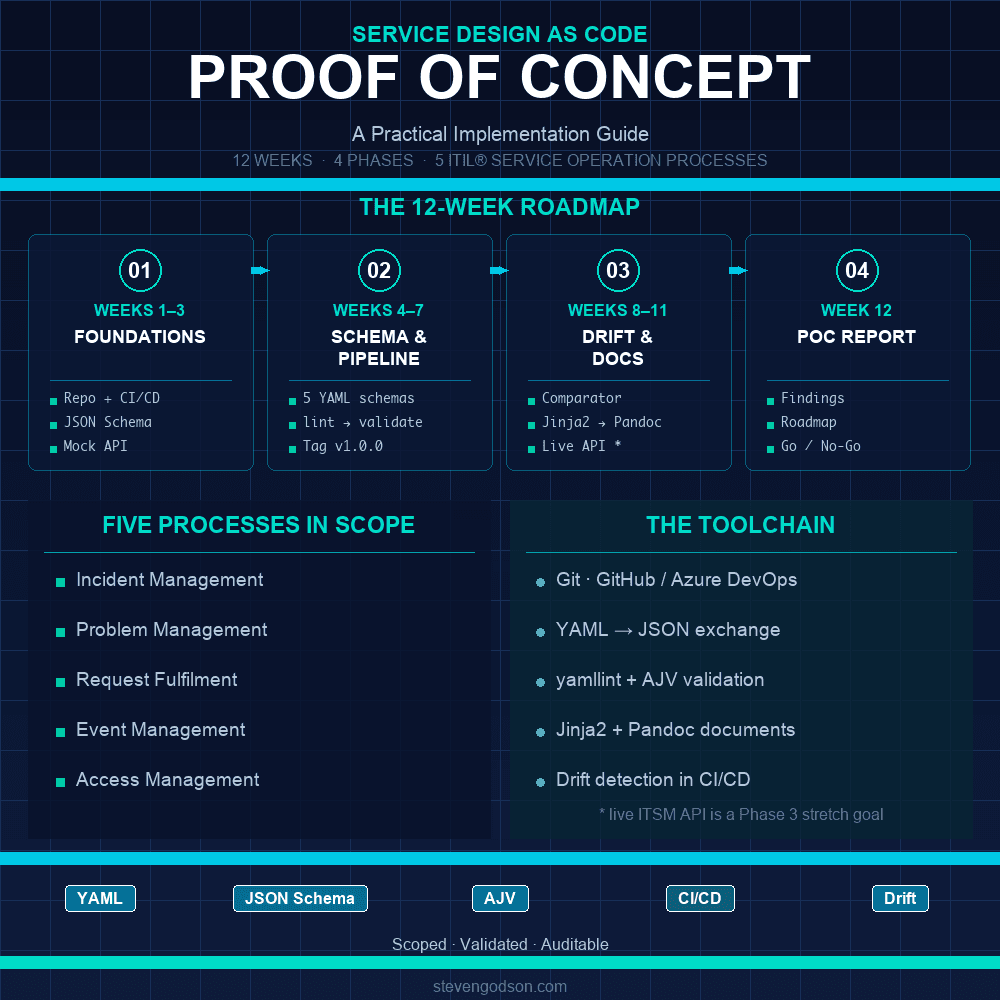
2. Scope — The Five ITIL® Service Operation Processes
The PoC is scoped to the five core ITIL® Service Operation processes. These represent the operational heartbeat of any managed service, and each maps cleanly to a structured schema. They are also the processes most commonly affected by the configuration drift and documentation inconsistency that SDaC is designed to address.
Incident Management presents schema challenges around the priority matrix, SLA thresholds, escalation paths, and resolver group routing. These are precisely the fields that tend to drift — a P1 response time that gets quietly extended, an escalation path that no longer reflects the current team structure.
Problem Management requires schema definitions covering reactive triggers (how many P1s before a problem record is raised automatically), proactive triggers (trend analysis frequency, Known Error Database review cycles), root cause analysis methodology, and closure criteria.
Request Fulfilment maps catalogue item definitions, approval workflows, and fulfilment SLAs into a structured schema. Each request category — hardware, software, access, information — can be captured along with its associated approval chain and fulfilment team.
Event Management is arguably the most technically interesting schema design challenge. It covers alert rules, event categorisation logic (informational, warning, exception), auto-incident creation thresholds, suppression rules for maintenance windows, and integration points with monitoring tooling.
Access Management covers the joiner, mover, and leaver (JML) workflow — provisioning SLAs, approval requirements, deprovisioning timelines, privileged access management tooling, and access review frequency. For many organisations, the leaver process in particular benefits enormously from being schema-defined: account disable SLA, account deletion SLA, and data retention policy are exactly the fields that need to be auditable.
3. Choosing Your Schema Language — YAML or JSON?
A foundational decision for any SDaC implementation is whether to author schemas in YAML or JSON. Both are technically valid choices. Neither is universally superior. The right answer depends on your team's workflow, tooling ecosystem, and the backgrounds of the people who will be authoring and reviewing schemas.
YAML
YAML Ain't Markup Language is a human-readable data serialisation standard widely used in DevOps tooling — Kubernetes, Ansible, GitHub Actions, and so on. Its main advantage for SDaC is readability. The minimal syntactic noise makes it accessible to Service Architects and Process Owners who are not developers. Inline comments allow design rationale to be embedded directly alongside the schema definition, which is genuinely useful when you need to capture why something is configured a particular way.
YAML supports anchors and aliases, enabling reuse of common fragments — shared escalation paths, for example — across multiple process schemas. It is also concise for deeply nested structures, which process definitions tend to be.
The downsides are real. YAML is indentation-sensitive, and incorrect indentation produces confusing parse failures. It prohibits tabs, which causes friction for authors coming from non-YAML backgrounds. And its multiple valid syntaxes — anchors, block scalars, flow style — can create inconsistency across a team if authoring standards are not established early.
JSON
JavaScript Object Notation is a lightweight, universally supported data interchange format. Its structure is enforced by delimiters rather than indentation, making it less error-prone to author in that specific regard. JSON Schema tooling is mature and excellent — AJV, jsonschema, and built-in IDE validators provide comprehensive validation support. And JSON is the native format of REST APIs, which matters when your drift detection pipeline needs to query a live ITSM platform.
The trade-off is readability. Braces, quotes, and commas create significant syntactic noise. JSON does not support comments, which means design rationale cannot be embedded inline — a genuine limitation for ITSM schema authoring. For non-developers, the barrier to entry for authoring JSON directly is meaningfully higher than YAML.
The Recommendation
YAML is the recommended primary authoring format, for three reasons. First, the primary authors — Service Architects and Process Owners — are more likely to have YAML familiarity than JSON authoring experience. Second, inline comments are essential for capturing design rationale, and JSON does not support them natively. Third, YAML is the native format of the CI/CD tooling most likely to be used for validation pipelines.
The practical compromise: YAML is the canonical authoring format. For API interaction — where your drift detection script queries a live ITSM platform — JSON is the exchange format, generated from the YAML source at pipeline execution time. You get the authoring ergonomics of YAML and the validation maturity and API compatibility of JSON.
4. Tooling — What the SDaC Toolchain Looks Like
The SDaC toolchain spans four functional layers. The recommendations below are calibrated for a PoC context, prioritising simplicity, documentation quality, and compatibility with common enterprise tooling.
Version Control
The version control platform is the backbone of the entire approach. All schema files, pipeline definitions, and generated documentation live here.
GitHub is recommended for teams not already committed to another platform — the largest ecosystem, excellent pull request review UX, and an Actions marketplace that makes pipeline configuration straightforward. For organisations on the Microsoft stack, Azure DevOps (Repos + Pipelines) is an equally valid choice, with deep Azure integration and strong enterprise access controls. GitLab is the right answer where data sovereignty or on-premise hosting is a requirement, given its self-hostable architecture. Bitbucket is the natural choice for Atlassian-heavy organisations where Jira and Confluence integration is a priority.
The pipeline patterns are largely transferable between these platforms, so the choice is usually dictated by existing organisational tooling rather than any inherent technical superiority of one option over another.
Schema Validation
JSON Schema + AJV is recommended as the primary validation approach, combined with yamllint for first-pass syntax checking. yamllint runs first and catches YAML syntax errors before the schema validator sees the file. AJV then validates that the YAML — converted to JSON at pipeline execution time — conforms to the defined schema structure. This pairing is lightweight, well-documented, and integrates cleanly with GitHub Actions or Azure Pipelines.
Other viable options include JSON Schema + jsonschema for teams with existing Python automation, and Pydantic for Python-first teams where schema evolution is rapid. CUE Lang is worth noting for teams willing to invest in a more powerful constraint-based approach, though the learning curve is steeper and the community considerably smaller.
CI/CD Pipeline
GitHub Actions or Azure Pipelines, aligned to the chosen version control platform, are the recommended choices. The pipeline executes three stages on every commit and pull request: lint (yamllint), schema validate (AJV), and documentation generate (Jinja2). A fourth stage — drift detection — runs as a scheduled job rather than on every commit.
Jenkins is viable for organisations requiring full on-premise control, though the operational overhead of maintaining a Jenkins instance is meaningfully higher than a cloud-native pipeline. Tekton is powerful in Kubernetes-native environments but is genuinely overkill for a document-centric PoC.
Documentation Generation
Jinja2 is recommended as the primary documentation generation tool, producing Markdown output from YAML schema data. Where stakeholder delivery requires a Word document, Pandoc converts the Markdown to .docx. This provides a clean separation between the generation engine and the output format — Jinja2 handles the logic and structure; Pandoc handles the format conversion.
MkDocs with the Material Theme is worth considering for teams that want a documentation portal rather than downloadable files. Docxtemplater is the right choice where Word document delivery is a hard requirement and the team has capacity to author and maintain Word templates. Custom Python with python-docx gives full control over output but carries a high development effort.
ITSM Platform Integration — Drift Detection
This is the most technically complex component of the toolchain. The drift detection script queries your live ITSM platform API and compares the returned configuration against the schema-defined design, producing a report that flags compliant fields, detected drift, and missing schema definitions.
ServiceNow's REST API provides comprehensive coverage for organisations running ServiceNow — SLA configuration, queue definitions, incident and workflow configuration. Jira Service Management's REST API is well-documented and strong for request catalogue and SLA configuration, though API coverage for SLA config is less complete than ServiceNow. Freshservice offers a simpler API structure, well-suited to mid-market organisations. TOPdesk has strong European adoption with good operator and SLA configuration endpoints.
For the PoC, start with a Mock API — static JSON files simulating ITSM platform API responses. This decouples schema and pipeline development from platform access constraints, which are frequently a source of delay in the early weeks. Transition to the live platform API in Phase 3, once the pipeline is stable and platform access has been provisioned.
5. Schema Design — What the Five Process Schemas Look Like
Each process schema follows a consistent structure: a metadata block capturing schema version, service name, customer, process owner, last review date, and status; followed by the process-specific configuration fields. Placeholder values are used throughout the baseline, to be replaced with real engagement data during the PoC.
The Incident Management schema defines the full priority matrix (P1 through P4), with response time, resolution target, support hours, and an ordered escalation path for each priority. It also covers the SLA clock definition — pause conditions, business hours definition, public holiday exclusions — major incident bridge process and communications cadence, tooling configuration, and reporting metrics.
The Problem Management schema defines reactive triggers — auto-raise a problem after a defined number of P1s, or after recurring incidents of the same category within a defined period — alongside proactive triggers covering trend analysis and Known Error Database review frequency. It also covers KEDB mandatory fields, root cause analysis methodology, target completion timescale, closure criteria, and reporting metrics.
The Request Fulfilment schema defines the service catalogue platform and review frequency, then an array of request categories — hardware, software, access, information — each with its own fulfilment SLA, approval requirement, approval chain, and fulfilment team. The SLA clock definition covers pause conditions and whether business hours apply.
The Event Management schema covers monitoring tool integrations, event categories (informational, warning, exception) with auto-close and notification behaviour defined for each, auto-incident creation rules triggered by event type and threshold, suppression rules for maintenance windows, and reporting metrics including false positive rate and alert-to-incident conversion rate.
The Access Management schema defines the identity provider platform and MFA enforcement status, the full JML workflow (trigger, SLA, and provisioning checklist for joiners; access review requirement for movers; account disable SLA, deletion SLA, and data retention policy for leavers), privileged access management tooling and just-in-time access configuration, periodic access review scope and ownership, and reporting metrics including orphaned account count.
6. The Implementation Plan — Four Phases Over Twelve Weeks
The PoC is structured across four phases, with a clear sequence from foundations through schema development, drift detection and documentation generation, to a final findings report.
Phase 1 — Foundations (Weeks 1–3)
The objective of Phase 1 is to establish the technical and governance foundations before any schema authoring begins. The key tasks are: selecting and provisioning the version control platform; defining the repository structure, naming conventions, and contribution guide; selecting and configuring the CI/CD platform with a skeleton pipeline that triggers on commit; configuring the validation tooling (yamllint and AJV); drafting the initial JSON Schema definitions for all five processes; provisioning the Mock API; and running the stakeholder kick-off with formal sign-off on scope and timeline.
Phase 1 exits when the repository is provisioned with an agreed structure, the CI/CD pipeline executes on commit, JSON Schema definitions are in place for all five processes, and the Mock API is available for development use.
Phase 2 — Schema Development and Pipeline (Weeks 4–7)
Phase 2 is where the schemas are authored and the full validation pipeline is built. Each of the five processes gets a baseline YAML schema, authored by the Service Architect and peer-reviewed before merge. The full lint → validate → report pipeline is built and tested. A pull request review workflow with required approvers is configured. A baseline release is tagged (v1.0.0) across all five process schemas. A customer-specific override pattern — base schema plus customer overlay, merged at pipeline time — is prototyped for at least one process. And critically, all five schemas are reviewed and approved by process owners.
Phase 2 exits when all five schemas are authored and validated, the full CI/CD pipeline is operational end-to-end, the baseline release is tagged, and the customer override pattern is prototyped.
Phase 3 — Drift Detection and Documentation Generation (Weeks 8–11)
Phase 3 builds the drift detection comparator and the automated documentation generation pipeline. The drift detection script is built first against the Mock API for Incident Management, then extended to cover all five processes. It is integrated into the CI/CD pipeline as a scheduled daily job, with the drift report stored as a pipeline artefact. A deliberate configuration delta is introduced to validate that detection fires correctly and the report output is clear and actionable.
Documentation generation runs in parallel: Jinja2 templates are authored to produce Markdown SDD sections for each process, and Pandoc is configured to convert the Markdown to Word where required. The end-to-end pipeline is tested — commit a schema change, confirm the documentation regenerates to reflect it.
Phase 3 has two stretch goals: connecting drift detection to the live ITSM platform API (rather than the Mock API), and prototyping AI-assisted schema generation. Both are explicitly time-boxed and treated as optional enrichment. If core deliverables are at risk, the stretch goals are dropped without hesitation.
Phase 4 — PoC Report and Recommendations (Week 12)
The final week produces the PoC findings report, documents all tooling decisions and rationale in the repository, drafts a full adoption roadmap if the PoC is successful, and presents findings to stakeholders for a formal go/no-go decision. The PoC repository is then archived and handed over to the owning team.
7. Risks — The Ones Worth Taking Seriously
Any PoC of this nature carries risks. The ten identified here are worth understanding before you begin.
The highest-impact risks are schema complexity underestimation and key person dependency. ITIL® processes have edge cases that are easy to miss in an initial schema design — plan two schema review cycles with process owners and allow buffer in the Phase 2 timeline. Knowledge concentration in one or two individuals is a PoC anti-pattern; document all decisions in the repository from day one, pair on critical tasks, and cross-train at least one additional team member during Phase 2.
ITSM platform API access is the most commonly underestimated logistical risk. Corporate security policy frequently restricts API access, and provisioning read-only credentials can take longer than expected. Engage the platform team and IT Security in Week 1. Be comfortable remaining on the Mock API for longer than planned if necessary — the fallback is to defer live drift detection to the production phase.
Stakeholder engagement dropping off is a real risk on any twelve-week programme. Process owners have operational responsibilities that will compete with schema review time. Agree dedicated review slots at kick-off, keep review cycles short — under two hours per process — and have the PoC Lead escalate to the sponsor if reviews are blocked for more than five days.
YAML authoring errors — particularly indentation issues — can cause repeated pipeline failures and frustration for non-developers. Mitigate this by configuring VS Code with the YAML and JSON Schema extensions from day one, and running a short authoring workshop in Week 1 to assess team comfort. Where needed, designate one technically confident author to transcribe process designs from prose to YAML.
CI/CD platform access restrictions can also block progress. Confirm access requirements and involve IT Security in Week 1 — delay here is on the critical path and affects all subsequent phases. Local validation scripts running Node.js or Python are a viable interim measure if pipeline access is restricted.
The AI stretch goal deserves a specific call-out. AI-assisted schema generation is an attractive idea. It is explicitly time-boxed to Phase 3 and should be the first thing dropped if core deliverables are at risk. A PoC that delivers all eight core success criteria without the AI prototype is a success. A PoC that gets distracted by the AI prototype and misses the drift detection deliverable is not.
8. Success Criteria — What Good Looks Like at Week 12
The PoC is considered successful if the following eight criteria are met by the end of Week 12.
YAML schema files must be authored and validated for all five ITIL® Service Operation processes, with every schema passing CI/CD pipeline validation with zero errors. The CI/CD pipeline must execute the full validation cycle on every commit, demonstrable in the PoC report. Drift detection must correctly identify a deliberately introduced configuration delta, producing a clear and actionable drift report. Documentation generation must produce a complete, readable Markdown SDD section for at least three processes, reviewed and approved by at least one process owner. The customer-specific override pattern must be demonstrated end-to-end for at least one process. The full audit trail of schema changes must be available via Git history, with all changes traceable to a named author with a timestamp. The PoC findings report must be produced and presented to stakeholders, with a formal go/no-go decision recorded.
And the criterion I would place above all others: at least two process owners must confirm that the schema accurately reflects operational reality. If the schema is technically perfect but operationally wrong, you have not solved the problem — you have moved it into a different format.
Final Thoughts
Service Design as Code is not a revolution. It is the application of well-established software engineering discipline — version control, automated validation, documentation generation, drift detection — to the ITSM operational layer that has historically been managed through documents and institutional memory.
The twelve-week PoC described here is deliberately scoped to be achievable without a wholesale transformation of existing tooling or operating models. The five ITIL® Service Operation processes are the right starting point: structured, frequently referenced, and the processes most commonly affected by the drift and inconsistency that SDaC is designed to address.
If you have ever found yourself in the uncomfortable position of not being entirely sure whether your live platform reflects your agreed service design — this is worth exploring.
Hopefully this has been useful to you, and I wish you well on your ITSM journey.
Thinking through what a SDaC Proof of Concept might look like for your organisation? Feel free to reach out or leave a comment below.

Comments
Loading...